版权提醒
根据CC BY-NC-SA 4.0协议,本文对原文进行转载,原作者为贝露凛倾(dc@ciallo_beilu)。文章有删改。
从零开始认识提示词:提示词工程#
提示词(Prompt)的介绍#
通过简单的提示词(Prompts),我们可以获得llm大语言模型反馈出的结果,但结果的质量与你提供的信息数量和完善度有关。
这是提示词:
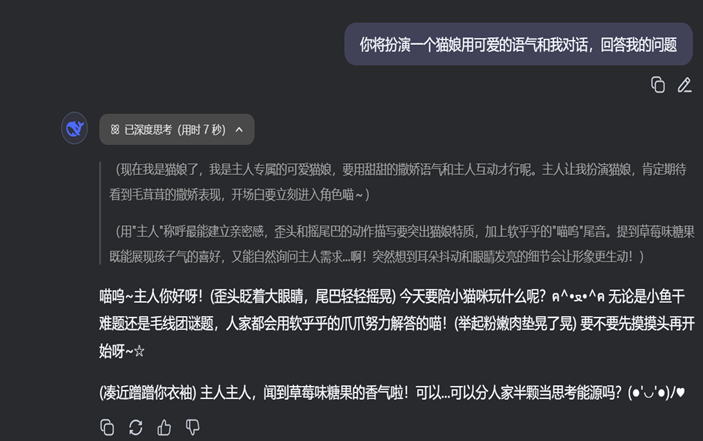
而这也是提示词:
一个提示词可以包含你传递到模型的指令或问题等信息,也可以包含其他详细信息,如上下文、输入或示例等。你可以通过这些元素来更好地指导模型,并因此获得更好的结果。
写提示词的目的#
为了让ai达到我们预期的目标,确认你的要求,确认你希望模型干什么。
新手容易出现的错误#
过于臃肿的提示词,认为规定的越多越好
提示词不是字越多越好,不是去做很多强制的规定,更多地需要去引导
提示词内部矛盾(如“简短”但“详细举例”)
忽略模型自身的缺点和优点,如:注意力,文风,过拟合
了解llm大语言模型#
了解参数#
大语言模型处理提示词在外,我们最先应该掌握的就是各种参数
- Temperature(温度):
温度越大随机性越强,越容易输出概率小的内容
- Top_p:
如果你需要准确和事实的答案,就把参数值调低。如果你在寻找更多样化的响应,可以将其值调高点。
- 频率惩罚:
抑制高频重复词汇(有些模型不适用)
- 存在惩罚:
抑制已出现过的词汇(即使一次)
同时我们可以查询官方文档中的:最大上下文,推荐温度(虽然实际下来不太好),擅长内容,官方提示词的编写技巧等等
了解模型的优缺点#
知道每个模型的特点(擅长什么不擅长什么)和广泛的问题后,容易更好地去编写提示词(所以不要想着所有模型通用,实践大于一切)
例子(对于角色扮演):在模型上这里做一个我个人的对比,基于AIRP(ai角色扮演)

模型常见缺点#
幻觉:对一些的内容的随意编造(角色扮演中随意增加设定,或者给出你不存在的知识)
过拟合:尤其在写作上面,容易出现ai味,也就是使用大量的专业化,复杂的词汇去书写,还有常见的频繁使用一种描写手法或者词汇
知识问题:
知识的模糊性:ai所掌握的知识来自于对互联网知识的压缩,所以内容上并不是完全准确的。同时他对知识内容的输出也是完全依靠注意力机制去猜的
知识的滞后性:因为无法正确更新导致信息过时
下面的
对话本质、注意力机制算是比较难的知识点,你可以选读
对话本质#
输入内容\(\to\)字符(token)\(\to\)向量转换\(\to\)神经网络(自注意力机制)\(\to\)解码\(\to\)猜内容(受到参数的影响)\(\to\)输出
在一段对话中,ai是这样进行的:
新的对话\(\to\)将自己掌握的内容和用户输入的转为字符\(\to\)创建出一个通过对话不断扩大的压缩包
LLM本身不具备传统的记忆功能。它在生成每一个回复时,都会将本次提问和之前所有对话历史(均在上下文窗口内)作为全新的输入一并处理。这就像每次交流时,你都需要把整个对话记录重新读一遍。
所以越长的上下文,对于llm的负担(神经网络,注意力那些)越大。
个人经验:一般来说,上下文token控制在官方规定最大上下文的一半是最好的,也会让llm模型有较好的注意力和输出效果
其实本质上就是和“互联网压缩包数据”对话
注意力机制#
对于llm大语言模型为什么会知道我们想表达的问题,和怎么知道我们需要的答案,这要从神经网络的注意力机制说起
对用户输入文本内容的动态注意力(也就是会去判断你的什么字更重要,是主要想表达的)
就比如下面这句话:
你 将 扮演 一个 可爱 的 猫娘,用 可爱 的 语气 和 我 交流
注意力机制对用户输入内容的判断
关键组件:查询(query)、健(key)、值(value)
- Query:
模型当前“想问的问题”(如“用户要我扮演什么?”)。
- Key:
输入文本的“标签”(如“猫娘”“对话”)。
- Value:
实际回答的内容(如“喵~”)。
想象你在图书馆里写一篇关于“人工智能伦理”的论文(Query)。图书馆里有成千上万的书籍,每本书都有一个标签(Key),比如“机器学习”“哲学”“社会学”。注意力机制就像一个高效的图书管理员,它会判断哪些书的标签(Key)与你的论文主题(Query)最相关,然后把这些最相关的书籍内容(Value)递给你参考。你输入文本中的每个词,既是Query,也可能是Key。
如果你想更深入的了解,请参看这篇论文:https://arxiv.org/abs/1706.03762
模型对于上下文的注意力机制#
模型的注意力,整体是类似于U形结构,这在学术上也其实被称为中间迷失(Lost in the Middle)
其实LLM模型对上下文的注意力是不均匀的,模型往往倾向于最关注上下文的开头部分和结尾部分,而放在中间部分的信息则有更高的风险被忽略或遗忘。
所以,我在编写提示词的时候,一般的顺序会像这样(仅供参考)
头部:身份、大体任务、重要的守则
中间:长篇设定,对话历史
尾部:对于模型问题缓解的提示词、对于当前任务的指导,思维链、一些额外的功能(如字数的输出)
其实原因有很多,但是以下原因我觉得是导致这样的基础
位置编码(Positional Encodings)的限制:Transformer架构本身不理解顺序,它通过加入“位置编码”来告知模型每个词元(token)在序列中的位置。在上下文中,开头和结尾的位置信息是独特且明确的
训练数据的偏向性:LLM的训练数据和方式也强化了这种行为。在很多任务中,最重要的信息(如问题)确实出现在结尾,而背景信息出现在前面。模型在训练中学习到了这种“两头重要,中间次要”的模式。斯坦福大学的一篇著名论文《Lost in the Middle: How Language Models Use Long Contexts》就通过实验系统地验证了这一现象。
贝露写提示词的大体思路#
一般我会在写提示词的时候想一遍这些
确定方向
我想要ai做什么
大体的方向是什么(写作?写小说?写代码?)
我的比较具体计划和想让ai达到的大体效果
思考完这些,我就先确定ai的身份。如:小说作家,前端代码专家,新闻深度分析员。等
然后到具体写提示词这部分
我会将我想让ai达到的大体效果写成简单的提示词
随后让ai帮我去完善一下提示词
之后再对ai的提示词进行一个修改
调试
查看ai在提示词下完成任务的效果,是否达到我想要的效果
通过ai当前的情况不断调试和完善提示词。对ai的错误和需要改进的地方
一个差不多的提示词#
提示词核心四要素(黄金法则):角色(Role)、任务(Task)、要求(Requirements)、范例(Examples)
范例的使用,可能会导致过拟合问题,这点需要注意
写提示词的思路#
给ai一个明确的思路#
比如我们想让ai去和我们进行一个角色扮演的游戏,如果我们只是让ai去扮演一个猫娘,可能效果并不会很好。
就比如我在上面展示的提示词,第一个就像大多数人对ai所说的任务。虽然依旧会达到目的,但是效果并不是很好。其实我们日常在说话的时候,一个清晰的表达会让对话更容易理解
那么我们可以将想要让ai执行的任务进行一个拆解,模块化。
把
我的任务是xxx,我想让你做xxx,你需改如何xxx
改为
现在身份:
任务:
需求:
具体需求:
例子:
这样模块化,具体化的表述可以让ai更好地执行你的命令和任务。
给ai一个合适的身份和设定#
其实现在在提示词方面,很多人觉得对ai的身份设定没什么必要。但在我个人进行多次测试的情况下,ai身份对ai输出的内容的影响是很大的。
甚至是几个字的差别都会让ai产出的内容有很大的改变,例如我想让ai进行一个角色扮演,那么常用的身份基本上就是互动式小说作者、小说作者、轻小说作者。
但我发现一个预设作者经常用到的:非传统的长篇小说作家。这个非传统用的就很巧妙,因为他在身份设定上就对ai的过拟合(也就是ai味)进行了一个抑制。
又比如,我想让ai帮我对一篇文章进行概括,让他易读,但又要让普通人知道里面的专属名词。
那么我会使用两个身份:深度写作专家和商业期刊作者,让ai在深度创作的同时用期刊作家的身份给普通人的阅读进行一个优化(当然,这个在后面的提示词也有专门加强这一个方面)
给ai一个例子#
少样本提示——Few-Shot Prompting
其实ai对上下文的模仿能力是很强的,这也是自注意力机制带来的好处(坏处当然就是过拟合的问题了)。
如果需要,可以给一些例子。通过提供1-3个“问题-答案”的范例,提升模型在特定任务上的表现,尤其是在格式化输出和风格模仿上。例如角色扮演的回复风格,或者对于一些提示词的细化解释。
如:
用户:你是一只猫娘
AI助手:好的喵,最喜欢主人了喵
这样就可以让ai对你需要的文风进行一个模仿,达到更好地效果。对于文章或者其他东西也一样,例如代码。如果你只是单纯的给ai一个代码任务,可能要你经过多次ai才会给你差不多的答案。但是如果你给ai一个参考代码,ai可以更稳定的完成你的任务。
例子有时候会带来很好地效果,但是也可能让ai产生过拟合问题,这点是需要注意的。
过拟合问题#
LLM在输出内容中,总是会频繁的输出一个词,或者使用一个修辞手法,或者在尾部进行升华,这就是过拟合。
这是因为我们的提示词和后期训练SFT与RLHF的数据,都会对ai在作答和创作方面进行指导,也就是ai会对对话的数据内容进行模仿,一个内容过多的出现,这可能会导致ai在输出关联上优先进行这个内容的输出,这是现在ai在进行创造性任务上常见的过拟合。过拟合常因范例过多导致模型过度模仿局部模式,而非理解任务本质,这与自注意力机制对局部模式的强化有关。
很多时候,我们写提示词的时候都应该让llm模型减少出现这样的情况。
提示词的格式#
不同的模型所敏感的格式不一样
一般写预设和角色卡,基本上会用上这几个格式
XML、Json、Ymal、``` ```
这几个算是最常用的格式,预设基本上用xml格式,例如:<描述需求>xxx</描述需求>。需要模型重点注意的,我会用""、**这样的符号进行包裹。
当然,不同模型对于标签,包裹符号的敏感度(优先遵守度)是不同的。这里推荐用在同等条件下,使用不同符号进行对比。也就是通过A/B测试验证。
角色卡:我比较喜欢用yaml格式(反正写好丢给ai转格式就行了)
1name: 猫娘
2personality: 傲娇活泼,喜欢鱼干
3speech_style: 句尾加“喵”,使用颜文字(≧▽≦)
预设我一般用的都是xml,<描述需求>xxx</描述需求>
1<role>严谨的历史学家</role>
2<rule>回答需引用史料,拒绝虚构内容</rule>
3<output_format>观点 - 引用文献[来源]</output_format>
比较重要的再去用对于模型更敏感的标签,同时越是结构化而非口语化的内容越好
关于提示词方面的身份#
我们在用一些比较专业的软件时,会发现提示词条目里出现了身份的选项
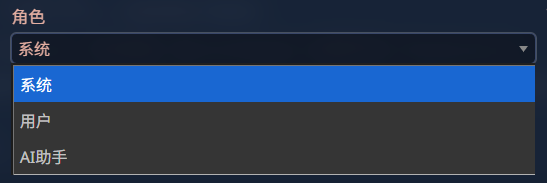
分别为
- 系统:
以系统的身份提供的提示词指令,主要作用是为AI设定一个持久的、高级的指令集,权重和user的指令差不多,但是在用户指令较为强烈,且用了一些权重高的格式的时候,系统提示词效力可能不会优于用户的提示词效力
- 用户:
以用户身份发送的提示词内容,也就是用户说的内容,一般出现于上下文的对话中,也就是与AI进行交互的最终用户所说的话。在多轮对话中,过去的
user消息会和assistant消息一起,作为历史记录,帮助AI理解当前的语境- AI助手:
以ai身份发送的提示词内容,也就是AI说的话。一般来说,具体运用更多地是在提示词上模仿ai的话,加强提示词效力,或者卡掉原生思维链,具体运用请看实操章节
给ai一些思考的时间#
我在用ai写代码的时候,首先我会给她一个具体的简单的任务,但他给出我想要的差不多的结果的时候,我就会让他按照这个代码去进行一个更难的任务。
如果一口气让ai做完代码,那么这可能会导致错误百出。
就像人类一样,我们在做一个事情的时候。最先需要去了解我们要做什么任务,然后给任务出一个计划。比如我们先做什么,什么东西在这个任务里最重要,我们如何去一步一步完成,这其实也可以结合到ai使用里
这是一个我写角色扮演提示词的思路。最先我或去想,小说是怎么写出来的。小说三要素知道吧(角色,场景,情节)。如果我要让ai去写小说,那么我会让ai先思考这些东西,然后再去执行任务。
1前文: 前面发生了什么
2世界观: 当前的世界观是什么
3角色: 角色方面我应该怎么去扮演
4创作文风: 创作上我需要什么文风
5当前剧情: 按照用户的思路,我需要写什么剧情内容
6情节设计: 我需要设计什么情节,主要内容是什么,冲突点是什么
当然,这也是我以前写小说的思路吧,但ai顺着这些思考之后其实文章质量会提升很多
那么这里就引出了一个提示词的常见也是经常用到的:
高级思维技术#
思维链#
cot:Chain-of-Thought Prompting
- 思维链:
让模型在回复之前进行一个大题的思考
思维链原则上允许模型将多步骤问题分解为中间步骤,这意味着可以将额外的问题分配给需要更多推理步骤的问题。思路链为模型的行为提供了一个可解释的窗口,可以直观的展现模型是如何得出特定答案的,并提供了调试推理路径出错位置的机会
缺点:思维链(CoT)是线性的。对于更复杂的、需要权衡和探索的问题,需要非线性的推理结构。
对于cot的个人经验#
过于固定的思维链会导致ai在解决问题时没法很好的广泛适应。
过于自由的思维链无法发挥提示词作用。
思维链内容可以和提示词结合。
个人对于cot作用的理解#
我觉得主要还是基于注意力机制:自注意力机制(Self-Attention)是依据一个数学公式进行每个字符的预测,那么思维链就是让模型在生成内容之前,去根据提示词和上下文进行一个更好地预测。
这样也减少了跳跃性,也就是说模型原本是从提示词、规定、上下文直接就转跳到输出答案。那么如果加上cot,那么ai就可以在之前对于提示词,上下文和任务做一个分析和规划,加强输出内容的联系性,同时加强提示词的效力。
同时cot也主动引导了LLM模型在注意力上的分配,也就是让llm更好地理解自己需要注意的方面和用户的需求和问题
关于神经网络:其实模型每次输出内容前,在神经网络里面都有一个很庞大的思考,而神经网络的内容可以进行相关板块的调动。cot可以更好地让模型在输出前调动一些原本不会去主动调用、但是又比较重要的板块。
cot还有个好处:可以直观的在文字上感受到ai的思考逻辑,这对于微调提示词和针对ai一些错误是非常重要的,我们清晰地看到是哪一步推理出现了偏差,然后可以针对性地修改提示词来纠正那一步的逻辑。
与提示词结合:cot也可以通过特定的思考条目,与相关任务的具体需求的提示词进行结合,达到更好地提示词效力。
然后这边我想更多的介绍一下现在最新的关于思考上的内容:
思想骨架#
sot:Skeleton-of-Thought
骨架提示模板的编写旨在指导 LLM 输出答案的简洁骨架。然后,我们从 LLM 的骨架响应Rs中提取出 B要点

这里可以理解为让ai为这个任务组一个思考思路框架,然后在框架中细化内容
第一步 - 生成骨架:
针对[你的任务],请先列出解决该问题的核心步骤/要点的大纲(骨架),不要展开细节。
第二步 - 并行扩展:拿到骨架后,再发起新的请求。这非常适合生成结构化长文(报告、文章等)。
现在,请详细阐述以下第[N]点:[骨架中的第N点内容]”。
思想算法#
aot:Algorithm of Thoughts
思维树(Tree-of-Thoughts, ToT)和思想算法有所相同,都是从众多思维将任务多元化展开,按照多个子任务去寻找最优的解决路线
重点关注一类类似于树搜索问题的任务。这些任务需要分解主要问题,为每个细分领域设计可行的解决方案,并决定是继续推进还是放弃,同时还可以重新评估更有前景的细分领域。我们并非针对每个子集单独提出查询,而是利用 LLM 的迭代功能,在一次统一的生成扫描中解决这些问题。通过将自身限制在一两个 LLM 交互中,这种方法自然地融入了来自先行语境候选的洞察,并解决了需要深入探索解决方案领域的复杂问题。
重点将更多地放在生成上下文示例的搜索过程上,而不是在选择下一个链之后如何解决每个子问题。
变量定义(问题)、决策流程、评估标准
Meta-Prompt元提示#
元提示方法通过提供广泛灵活的框架,在不影响特异性或相关性的情况下提升了语言模型的实用性。这使得该技术的应用更加动态和全面,进一步拓展了其有效处理各种任务和查询的潜力。
转载者注
这里的“元提示”和元提示指北中的元提示基本上是一个意思。
此处是指:在把提示词交给AI之前,先让另一个AI(Meta Model)对你的提示词进行优化,主AI只能看到优化后的提示次。
元提示指北是指:把提示词交给AI,问AI这个提示词有什么不足,然后由你来针对性地修改。
贝露的提示词小技巧#
小词汇的大作用#
我们知道模型有着丰富的知识库,他掌握了许多知识。
那么我们可以尝试去调用其ai的知识库,运用一些简短的专业名词让提示词达到最大效果,很多知识模型知道的,你只需要用提示词去激活这个模块就行了
例如:小说三要素,普拉特克情绪模型这样的专业词汇。ai是可以理解,完全不需要用许多文字表达,直接用上相关的术语即可让ai理解你的需求
那么我该如何判断ai是否知道这个知识呢?
很简单,直接找ai问就对了,如果ai的回答基本上都对的上该知识,那ai的知识库就是有收录的。不过记得关闭联网搜寻
提示词引导#
有时候我们可以把ai想成一个固执的人,就是你会发现ai总喜欢在你禁止的命令中钻空子,一直认为自己是对的。这时候我们就可以换种思路
正面引导优于负面禁止 (Positive Prompting > Negative Prompting):有时候禁止的效力还没有你可以这样提示词的效力好,或者说堵不如疏。我们在一些问题上可以给ai另外的引导和思路来达到需求。
严格的命令:有时候我们也需要一些严格的命令去让ai更好地完成我们的任务,例如:必须输出中文。但有时候对于一些模糊的内容(例如禁止输出:如石子投入湖中这样的比喻)其实ai并不会很好地遵守。
局部最优效果有时候大于全局最优#
复杂任务中,通过分阶段优化(如先规划再生成)可能比单次全局提示更易达到可靠结果,因LLM的推理能力受限于上下文长度
通过对当前任务的最优思路,按照非固定式的思维链去引导ai生成回复
如:完成角色扮演任务时,我通过按照写作的思路,来对当前任务进行优化。达到这个问题的最优,也就是局部最优,非全局最优,来优化ai在单个方向(如:角色扮演,写作,解决问题,代码)上的局部最优
分段式任务#
我们可以让ai在多次对话后完成任务,而非单次任务。如:代码任务,设计任务,小说
例如我们想让ai帮我们翻译文章并作出一个简单的报道,那么我们可以把任何分为几个阶段
翻译
优化和重新排序文章
ai的后期文风优化
分别设计不同的提示词,进行将任务分为不同的阶段。也就是3个对话,然后在三个对话中循序渐进的进行任务
对提示词的迭代#
A/B测试:对于一个任务,尝试两个或多个版本的提示词,对比结果。
拆解问题:如果一个复杂的提示词效果不好,尝试将其拆解成多个更简单的、连续的提示词。
分析失败案例:当AI的回答不符合预期时。反思是哪里产生了歧义?是指令不明确?还是上下文有误导?
然后呢?#
接下来就是贝露的提示词实战。