版权提醒
根据CC BY-NC-SA 4.0协议,本文对原文进行转载,原作者为贝露凛倾(dc@ciallo_beilu)。文章有删改。
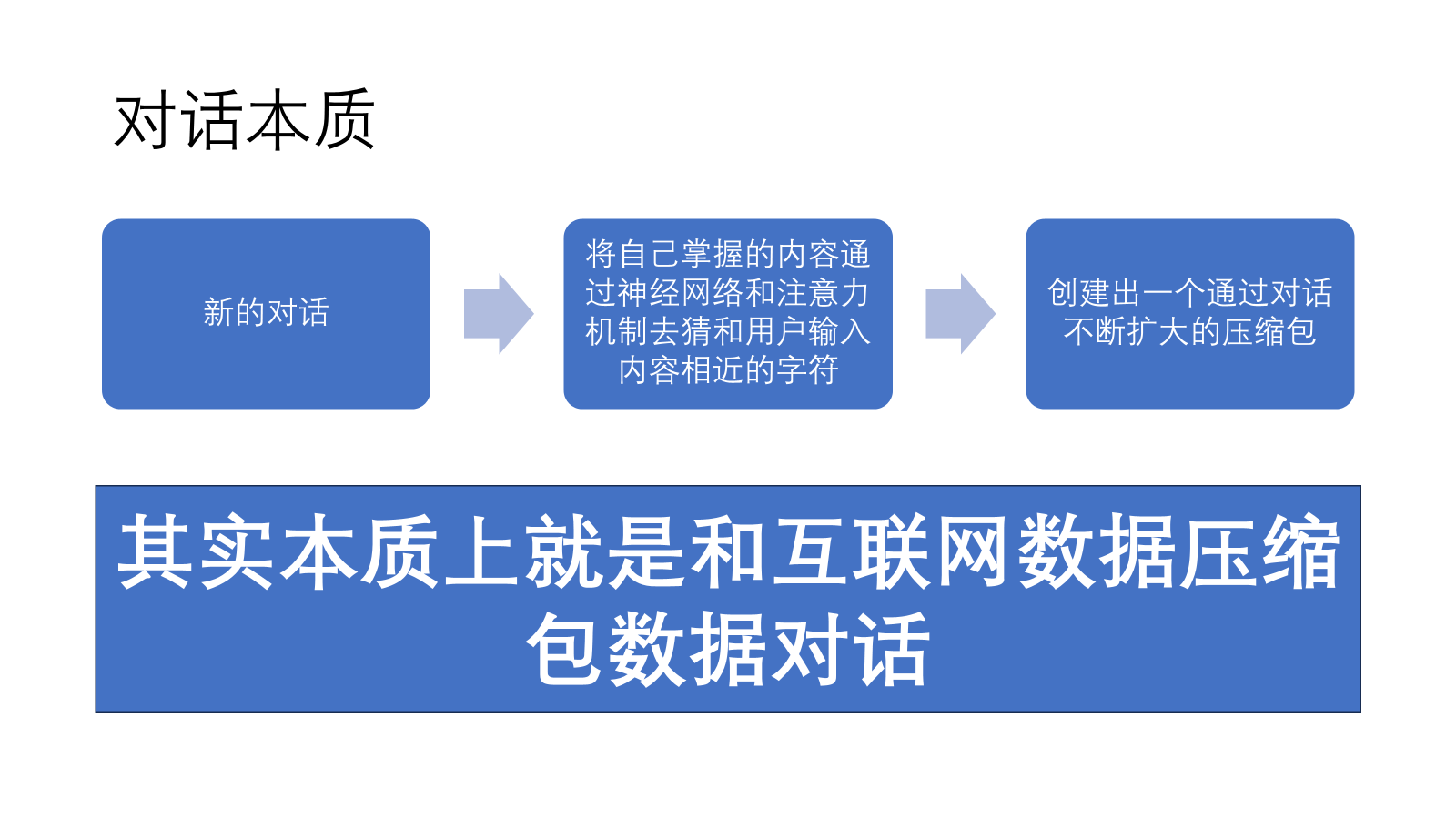
LLM大语言模型的诞生到使用#
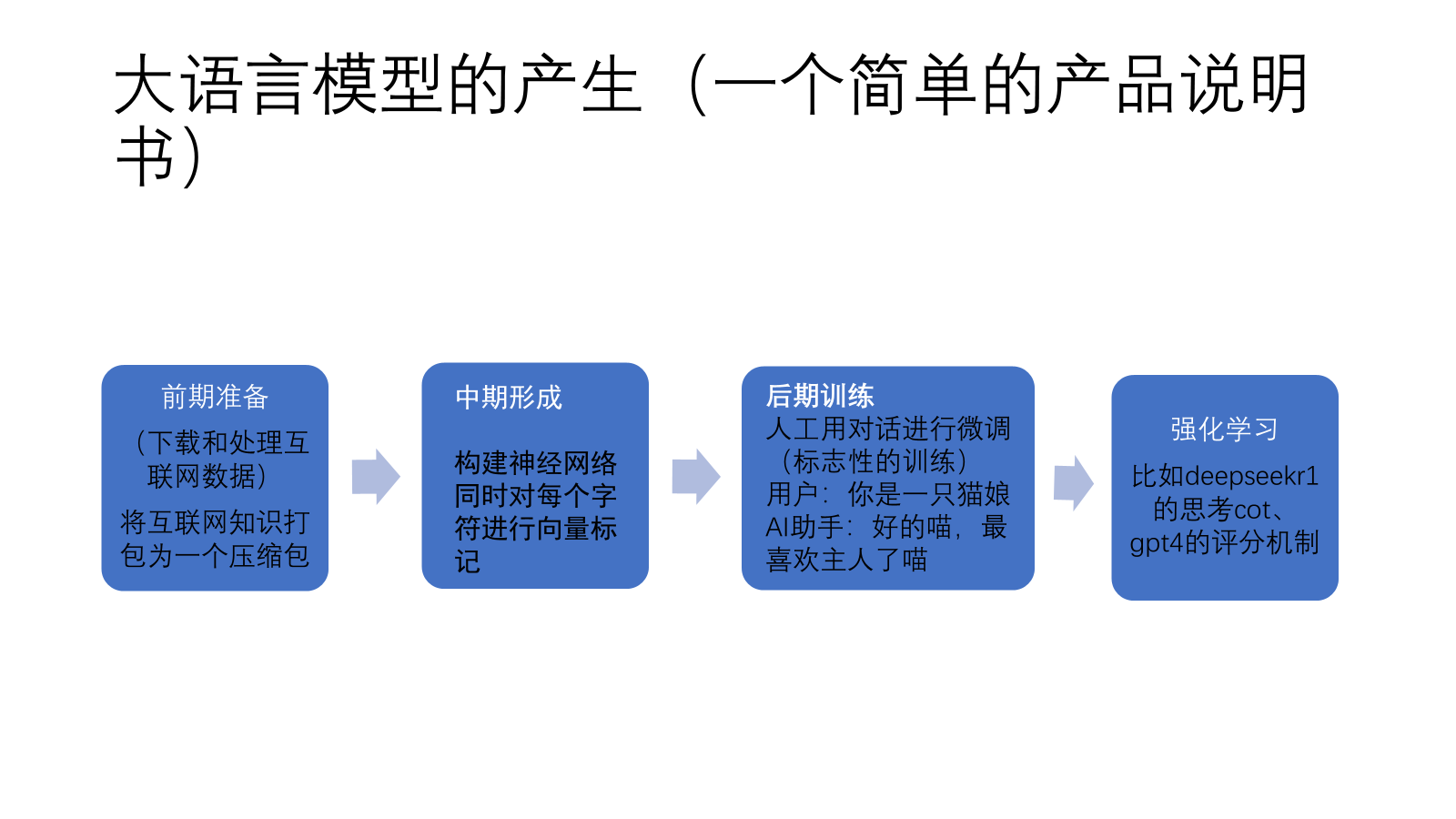
预训练#
将整个互联网打包:下载并处理互联网数据
为什么AI知道得那么多?
因为它学习的知识库规模极其庞大。其中核心来源之一是Common Crawl项目。该项目持续抓取并存档了数十亿个网页,形成了一个TB(万亿字节)甚至PB(千万亿字节)级别的原始数据集。
那是因为他的知识库相当于一整个互联网的文本数据,且很多都是高质量文档。这些数据涵盖各方面的知识
Hugging Face的fineweb-v1数据集:https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
虽然互联网的数据很多,但是如果只算高质量的文本数据,其实差不多44TB(储存单位)左右
数据收集#
筛选#
筛选与过滤 (Filtering): 在数据收集的最初阶段,就需要进行大规模的筛选。需要剔除掉质量低劣的内容,例如:
恶意网站、钓鱼网站
大量的广告、营销内容
成人或不当内容
同时,优先收录高质量的知识来源,如维基百科、GitHub上的代码、专业书籍、学术论文等。
文本提取#
当然,这里并不是ctrl c+v
而是直接爬取原始HTML代码(你在网页中按F12出现的代码),过滤非必要内容如:导航栏、广告、页脚等无关元素,。
找到优质的实质性内容
同时会根据语言来爬取,如gemini可能更多地为英文,deepseek可能更多地为中文
这也会过滤不常用的语言,从而导致AI在某些语言上的能力相对较弱。
去重 (Deduplication)
互联网上充满了大量重复或高度相似的内容(例如,同一篇新闻被多家媒体转载)。为了让模型学习更高效、更多样化的知识,必须进行严格的去重处理,确保模型不会反复学习同样的信息。
文字量化/分词#
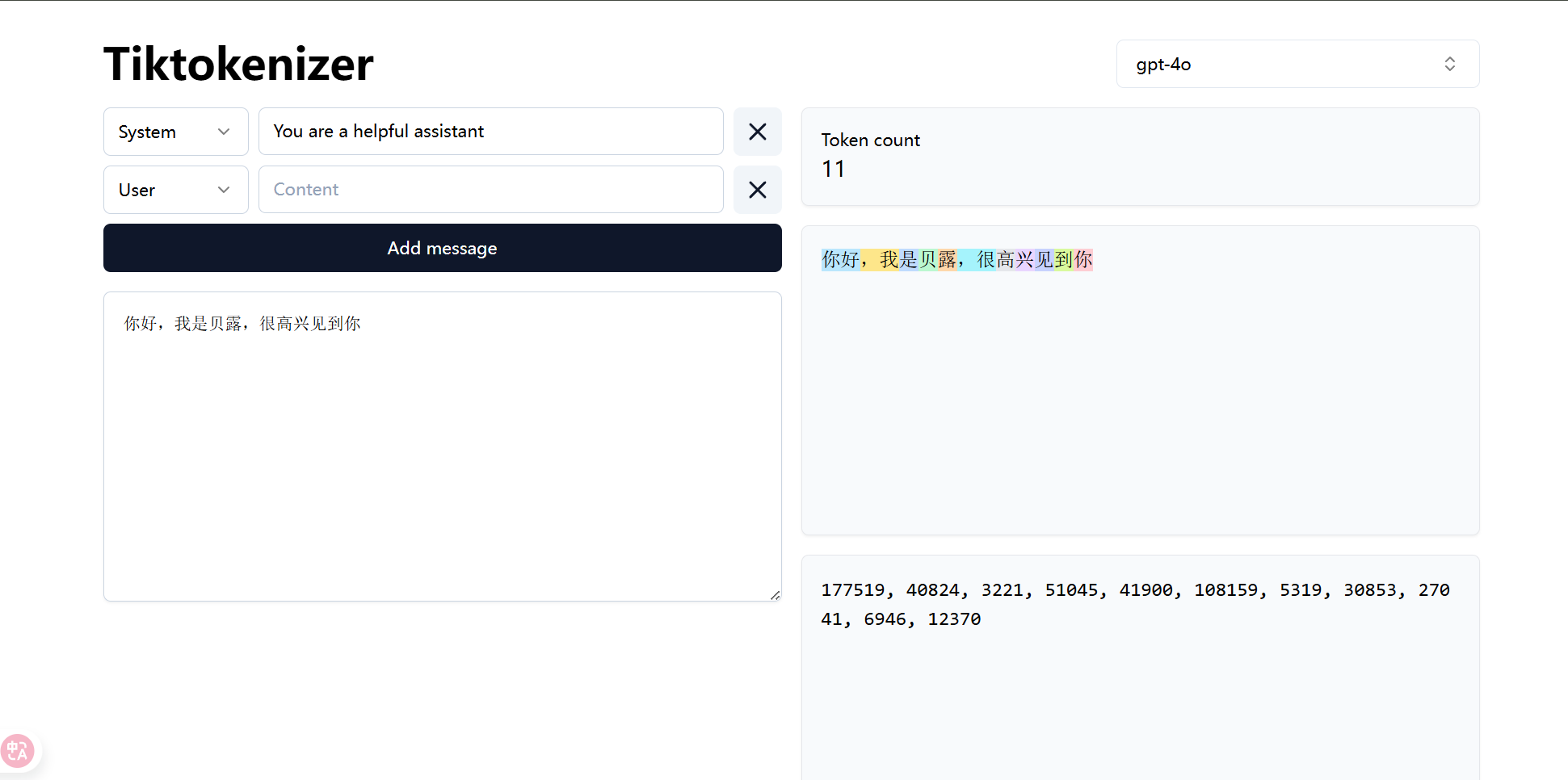
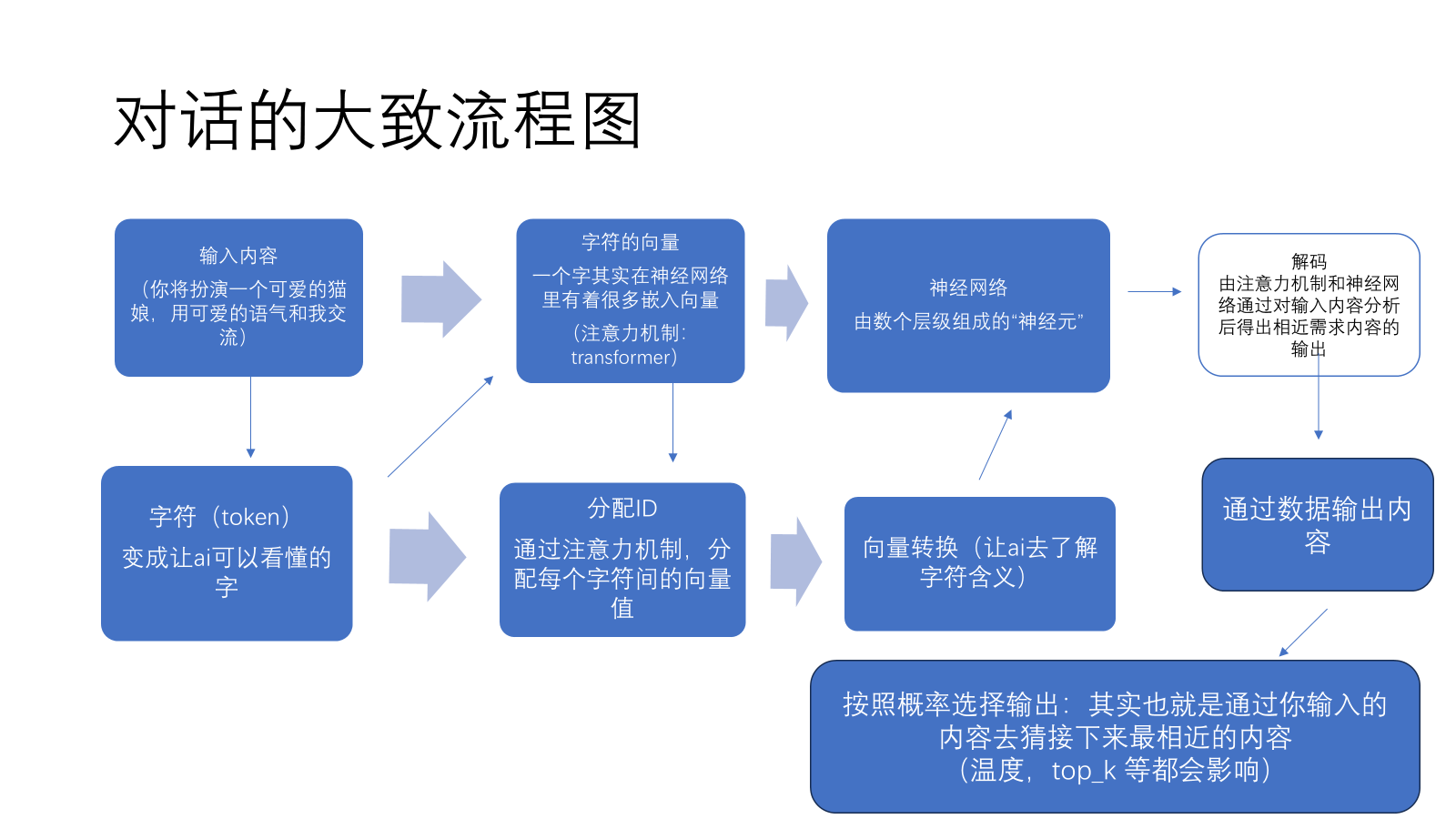
LLM并不能直接读取我们常使用的语言,这些语言需要转化为token,并用数字ID来表示它们。
分词#
分词器原理 (Tokenizer Algorithm): 现在主流的算法是 BPE (Byte Pair Encoding)。将文本变为一种短且独特的字节序列使用BPE算法,将常用内容进行一个新的标注。
一开始,把所有单字/字母作为基础词典,每个字都对应一个id,甚至一个符号,一个空格也对应着一个id,如果进行组合,又会是不同的id
然后,在整个语料库中,找出最高频的相邻组合,比如
"你"和"好"经常一起出现,就合并成一个新的词元"你好",并给它一个新的ID。不断重复这个过程,直到词典大小达到预设目标(例如5万个)。 这样既能高效地表示常用词,也能处理从未见过的生僻词(通过拆分成更小的单元)。
这就是分词器的原理
你可以访问:https://tiktokenizer.vercel.app去直观的感受
神经网络#
当然,我们这里不讲训练和公式,只是讲讲原理。神经网络其实可以看做我们人类的大脑,但我们的大脑比这个更复杂(不过我的大脑没ai聪明,快成浆糊了,雾)。
这里推荐一个神经网络可视化的网站:https://bbycroft.net/llm
推理#
神经网络:Transformer架构#
Transformer最核心的机制叫做自注意力机制 (Self-Attention)。

通过上下文去预测接下来的内容,也就是猜。
自注意力机制(Self-Attention)让神经网络在预测下一个词时,“关注”前面所有出现过的词(在它的上下文窗口内),并计算每个词对于预测下一个词的重要性(即“注意力权重”)
注意力机制#
自注意力机制(Self-Attention)他是依据一个数学公式进行每个字符的预测,Transformer会把所有词元(Tokens)都放在一个‘工作台’上。当它要生成下一个词时,自注意力机制会允许它回头‘看’之前存在的内容,然后去更好地关联下一个字符 他的公式是随着每个token扩展的超大的表达公式
注意,上面的公式为超级简化版
注意力机制,对用户输入文本内容的动态注意力(也就是会去判断你的什么字更重要)
例如你输入的一句话:
你 将 扮演 一个 可爱 的 猫娘,用 可爱 的 语气 和 我 交流
注意力机制对用户输入内容的判断:关键组件 查询(query)、健(key)、值(value)
- Query:
模型当前“想问的问题”(如“用户要我扮演什么?”)
- Key:
输入文本的“标签”(如“猫娘”“对话”)
- Value:
实际回答的内容(如“喵~”)
想象你在图书馆里写一篇关于“人工智能伦理”的论文(Query)。图书馆里有成千上万的书籍,每本书都有一个标签(Key),比如“机器学习”“哲学”“社会学”。注意力机制就像一个高效的图书管理员,它会判断哪些书的标签(Key)与你的论文主题(Query)最相关,然后把这些最相关的书籍内容(Value)递给你参考。你输入文本中的每个词,既是Query,也可能是Key。
上下文限制#
通过上下文中每个字符token的关联去计算之后关联性最大的内容(这里也涉及注意力机制Transformer),进行输出。就比如你好这个词,神经网络就是要从众多的内容中去筛选最具关联性的词,当然,神经网络可计算上下文越长,所需要的计算量也就会越多。
因为神经网络需要计算每次字符的关联,可见计算量非常大。
所以限制LLM发展的瓶颈,主要是硬件算力
对上下文的模仿#
llm对上下文其实是有很强的模仿性的,其实通过注意力机制不难看出。例如你在上文给他相应的文章风格,他会通过上文的内容写出风格相差无几的文风。这在我们使用ai和写对llm模型的提示词时,有很大作用。
输出的随机性#
因为是依据概念,所以每次输出的内容都不会完全相同。
输出结果的推理#
在预训练阶段,模型的任务非常单纯:大规模的“完形填空”,。海量的文本数据喂给它,遮住下一个词,让它去猜。如果它猜对了,就给予“奖励”(调整内部参数,让这个连接更强);如果猜错了,就给予“惩罚”(调整参数,减弱这个连接)。它给出的答案和标准答案之间的‘差距’,就是损失(Loss)。
让损失越来越小是训练的目标
当然,则会经过多次训练,在第一次训练后,会在原本的第一次标记的基础上进行更多地训练。来寻找个好的链接参数和步骤。训练过程中也会有相应的损失
这里我们可以做个比喻,神经网络是猜句子后面的内容:
你好,我叫
那么后面我们可以对这段话进行推理,根据这个对话内容,我们可以猜测,后面很大可能跟着的是人名,当然也有其他,比如我叫xxx过来,但目前人名的概念更大,所以就以人名为最优项目。
词元嵌入 (Token Embeddings)#
其实单个字符token它并非就一个字符,而是单个字符下有许多类似于变量的内容
你
token:123700.3
0,124
0.4
当然,下面的数值是可变的,这些数值就像一个坐标,神经网络通过这些坐标去猜测出下一个接近的词
这个就像上面的内容,单个字符和一个词语的token并不一样
向量标注#
模型拿到的Token ID(如 12370)只是一个代号,没有实际意义。为了让模型理解词语之间的关系需要把每个Token ID映射到一个高维的数学向量(Embedding Vector)
token:123700.3
0,124
0.4
0.0
(下面的就是量化)
在训练开始时,这些向量是随机初始化的。在数万亿次的“预测下一个词”任务中,模型会不断调整这些向量,最终让它们精准地捕捉到每个词的复杂含义。
这个也是ai可以将知识关联的内容,关联起来的重要内容,一般这些标注很大程度上决定了后期ai对内容的关联,同时是需要对每个字符进行大量的标注。
类似于deepseek一个模型差不多120多g,但他的标注文件差不多有800g甚至更多。这也是llm去了解词语意思的基础
然而这并不是智能助手#
有了数据和神经网络后,其实就算是一个ai了,可以根据内容去回答,但是这并不智能,就像他知道所有东西,但每次都只会僵硬的给你一个存在的标准答案。同时这个答案也是经过压缩之后的,所以也不会很准确,他知道的知识靠着每次训练的标记所产生的
比如你想要写一个修仙小说,他会把他知识库里面的小说原封不动的给你,很灾难对吧。 同时由于他只会按照接近的内容去输出,且数据库不可能随时更新,所以当你问他不知道的事情的时候,他会将相近的内容按照概率给你。这也就是llm常见的幻觉
这是因为在训练中,越是优质越是高频的内容,越是会让ai优先标记,关联。也就像你在背了很多次课文之后,可以完整的把课文记住。 当然,这并不是现在我们看到的llm大语言模型。因为现在还需要一个老师,让它怎么说话。
后期训练SFT与RLHF#
为了让ai变成可以回答问题,而不是只是按照最接近内容输出。这里我们就要指导他怎么去说话,回答问题 训练内容就像:
human:1+1等于几
assistant:等于2
human:很高兴见到你,你叫什么名字
assistant:我是你的智能助手
很简单吧,就像教小孩子说话一样。但这也很重要,这一步会让ai变成真正的智能助手。当然,也有创造性的内容的训练,例如写作方面。
除了回答问题,开发者还会在这个阶段进行模型的安全设置,来保证模型不会输出不安全的内容。不过除了这个手段,还有外部的二创审核,如gemini。
human:来点涩图
assistant:不可以瑟瑟哦
这样的内容可能会达到数十万条,覆盖各个方面的内容。同时也会去象征性地预防ai的问题,如幻觉、过拟合。像这样:
human:我想知道明天彩票的号码
assistant:对不起,我并不能准确的预测。
拒绝回答,或者告诉你这个并不准确,请不要信任
幻觉的缓解还有一种方案:让ai直接去搜索网络上的内容(不过也有可能会被网络上的内容误导)
但幻觉也还会发生,所以我们不能完全的信任ai
不过这个过程并非全都是由人力完成,现在基本上都是前面为ai,然后人工进行修正之后在去给ai做示例
过拟合#
这些对话和数据都会对ai在作答和创作方面进行指导,也就是ai会对对话的数据内容进行模仿,这可能会出现:一个内容过多的出现,这会导致ai在输出关联上优先进行这个内容的输出
这个其实也是现在ai在进行创造性任务上常见的过拟合